


We have seen the basic operation of convolution in the previous post.
In this post, we will be discussing padding in Convolutional Neural Networks. Padding is the number of pixels that are added to an input image. Padding allows more space for the filter to cover the image and it also helps in improving the accuracy of image analysis.
Broadly classified, there are two types of padding. They are valid padding and same padding.
Valid Padding:
It implies no padding at all. That is input image is fed into the filter as it is. So if we consider the input of the order (n), a filter of order (f) and take stride=1, we get the output image of order (n-f+1).
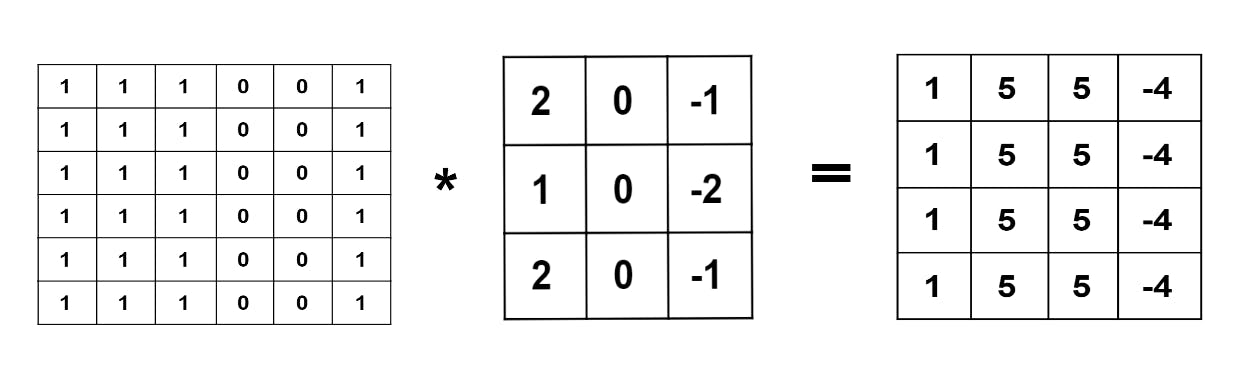
We can notice here the order of output image decreases. Hence we can clearly state that some information is lost as we traverse from input to the output. The example provided above is only for one convolutional layer. But in deep neural networks, there is more than one convolutional layer. Hence this obtained output image when passed through the filter in further steps, will result in further shrinkage in size.
Same Padding:
In the case of the same padding, we add padding layers say 'p' to the input image in such a way that the output has the same number of pixels as the input. So in simple terms, we are adding pixels to the input, to get the same number of pixels at the output as the original input.
So if padding value is '0', the pixels added to be input will be '0'. If the padding value equals '1', pixel border of '1' unit will be added to the input image and so on for higher padding values.
So if we consider the input of the order (n), a filter of order (f) and take stride=1, we get the output image of order (n+2p-f+1), if the padding layers added is equal to 1. We can either add zeros to the padding layer or the adjacent entry. The more commonly used method is to add zeros to the padding layer as shown below.
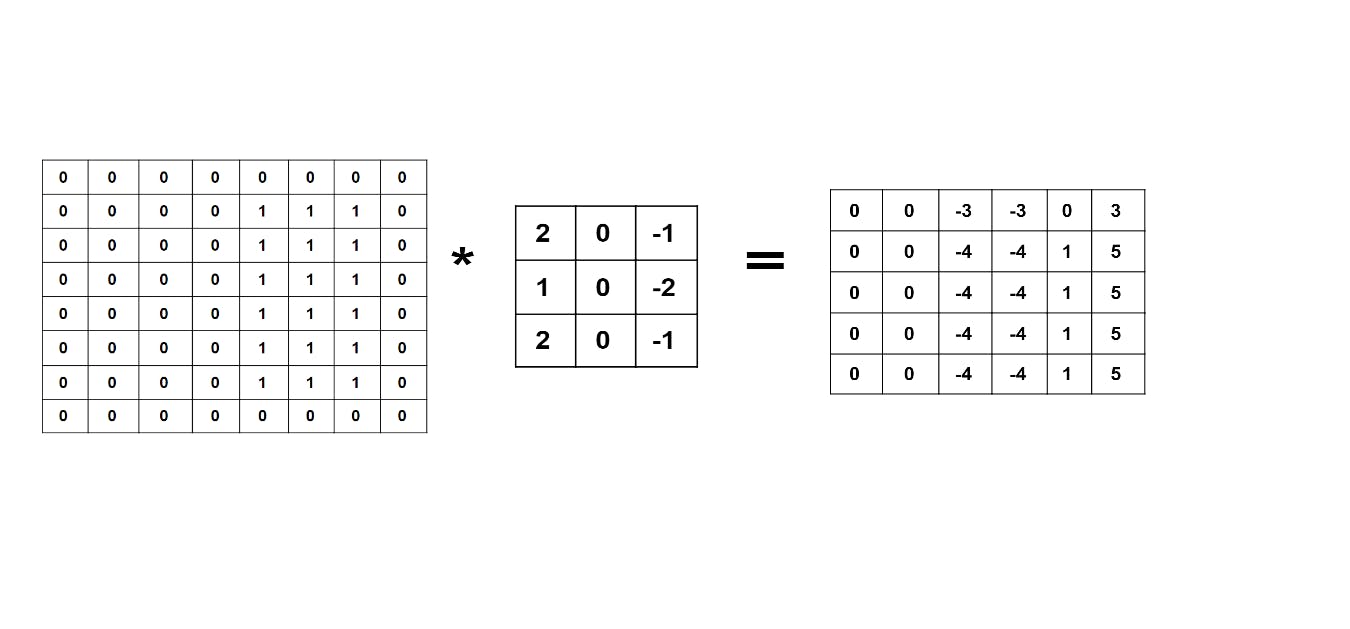 Hope you understood the concept. Thank you for reading.
Hope you understood the concept. Thank you for reading.